Reverse path forwarding (RPF) is a technique used in modern routers for the purposes of ensuring loop-free forwarding of multicast packets in multicast routing and to help prevent IP address spoofing in unicast routing.
Contents |
Multicast RPF
Multicast RPF, typically denoted simply as RPF, is used in conjunction with multicast routing protocols such as MSDP and PIM-SM to ensure loop-free forwarding of multicast packets. In multicast routing the decision to forward traffic is based upon source address and not on destination address as is the case with unicast routing. It does this by utilizing either a dedicated multicast routing table or alternatively the router's native unicast routing table.
When a multicast packet enters a router's interface it will lookup the list of networks that are reachable via that input interface i.e., it checks the reverse path of the packet. If the router finds a matching routing entry for the source IP of the multicast packet, the RPF check passes and the packet is forwarded to all other interfaces that are participating in multicast for this multicast group. If the RPF check fails the packet will be dropped. As a result the forwarding of the packet is decided based upon the reverse path of the packet rather than the forward path. RPF routers only forward packets that come into the interface that also hold the routing entry for the source of the packet, thus breaking any loop.
This is critically important in redundant multicast topologies. Because the same multicast packet could reach the same router via multiple interfaces, RPF checking must be integral in the decision to forward packets or not. If the router forwarded all packets that come in interface A to interface B and it also forwarded all packets coming in interface B to interface A and both interfaces receive the same packet, this will create a classic routing loop where packets will be forwarded in both directions until their IP TTLs expire. Even considering TTL expiry, all types of routing loops are best avoided as they involve at least temporary network degradation.
Unicast RPF (uRPF)
uRPF as defined in RFC 3704 is an evolution of the concept that traffic from known invalid networks should not be accepted on interfaces from which they should never have originated. The original idea as seen in RFC 2827 was to block traffic on an interface if it is sourced from RFC 1918 private addresses. It is a reasonable assumption for many organizations to simply disallow propagation of private addresses on their networks unless they are explicitly in use. This is a great benefit to the internet backbone as blocking packets from obviously bogus source addresses helps to cut down on IP address spoofing which is commonly used in DoS, DDoS, and network scanning to obfuscate the source of the scan.
uRPF dramatically extends this idea by utilizing the knowledge all routers must have to do their jobs, their routing table, to help further restrict the possible sources addresses that should be seen on an interface. Packets are only forwarded if they come from router's best route to the source of a packet, ensuring that:-
- Packets coming into an interface come from (potentially) valid hosts, as indicated by the corresponding entry in the routing table.
- Packets with source addresses that could not be reached via the input interface can be dropped without disruption to normal use, as they are probably from a misconfigured or malicious source.
In cases of symmetric routing, routing where packets flow forward and reverse down the same path, and terminal networks with only one link this is a safe assumption and uRPF can be implemented without much fear of problems. It is particularly useful to implement RPF on routers interfaces that are connected to singly homed networks and terminal subnets as symmetric routing is guaranteed. Using uRPF as close as possible to the real source of traffic also stops spoofed traffic before it has any chance of using internet bandwidth or reaching a router which is not configured for RPF and thus inappropriately forwarded.
Unfortunately, it is often the case on the larger internet backbone that routing is asymmetric and you cannot count on the routing table to point to the best route for a source to get to a router. Routing tables specify best forward path and only in the symmetric case does that equate to the best reverse path. Because of this common asymmetry it is important when implementing uRPF to be aware of the potential for asymmetry to exist to prevent accidental filtering of legitimate traffic.
RFC 3704 gives more details on how to extend the most basic "this source address must be seen in the routing table for the input interface" concept known as Strict Reverse Path Forwarding to include some more relaxed cases that can still be of benefit while allowing for at least some asymmetry.
As one final note, any device using a default route cannot use uRPF on the interface that the default route points to because all sources would be allowed to come from that interface and uRPF would not accomplish even as much as RFC 2827.
Unicast RPF confusion
RPF is often incorrectly defined as Reverse Path Filtering, particularly when it comes to unicast routing. This is an understandable misinterpretation of the acronym in that when RPF is used with unicast routing as in RFC 3704 traffic is either permitted or denied based upon the RPF check passing or failing. The thought being that traffic is denied if it fails the RPF check and is therefore filtered, however as per RFC 3704 the correct interpretation is that traffic is forwarded if it passes the RPF check. Several examples of the proper usage can be seen in documents by Juniper, Cisco, OpenBSD, and most importantly RFC 3704 which defines the use of RPF with unicast.
While uRPF is used as in ingress filtering mechanism, it is affected by reverse path forwarding.



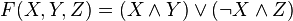



 denote the
denote the 
